GPT-Powered Stock Trading Research
Can a large transformer model act as an all-in-one, news-based trading bot? A senior research project.
Background
Back in the dark ages (yes, I mean before Chat-GPT took the internet by storm), transformer-based text generation models were known only to AI researchers and the nerdiest of programmers. It took until the release of OpenAI's GPT-2 in early 2019 before I joined the hype train. Like everyone else at the time, I wanted to co-opt the power of transformers for fun and profit, but alas OpenAI was only allowing other big-time researchers, or deep-pocketed corporations access to their groundbreaking technology. Thankfully in the meantime, Ben Wang and Aran Komatsuzaki were assembling a crack team of open-source gods to compete with OpenAI. Working at breakneck pace, they released GPT-J, a free and open competitor to GPT-2 and GPT-3 by early 2021, just in time for me to make use of their work in my senior research project for my college degree.
Timeline

My Research Project
Concept
In mid-2021, there was lots of excitement around the flexibility of large transformer models. I wanted to see if I could use GPT-J as an all-in-one news-based trading bot. The idea being, if a model has read enough of the internet as background, it should understand the context of a news article, and output a trading signal for a given company.
Input: News article about a company ⮕ Output: Buy/Sell/Neutral signal
Data gathering
For the best chance of success, I decided to fine-tune the GPT-J-6B model with data formatted like the prompts I intended to test with. I scraped and labeled 140,000 news articles from the below web sources:
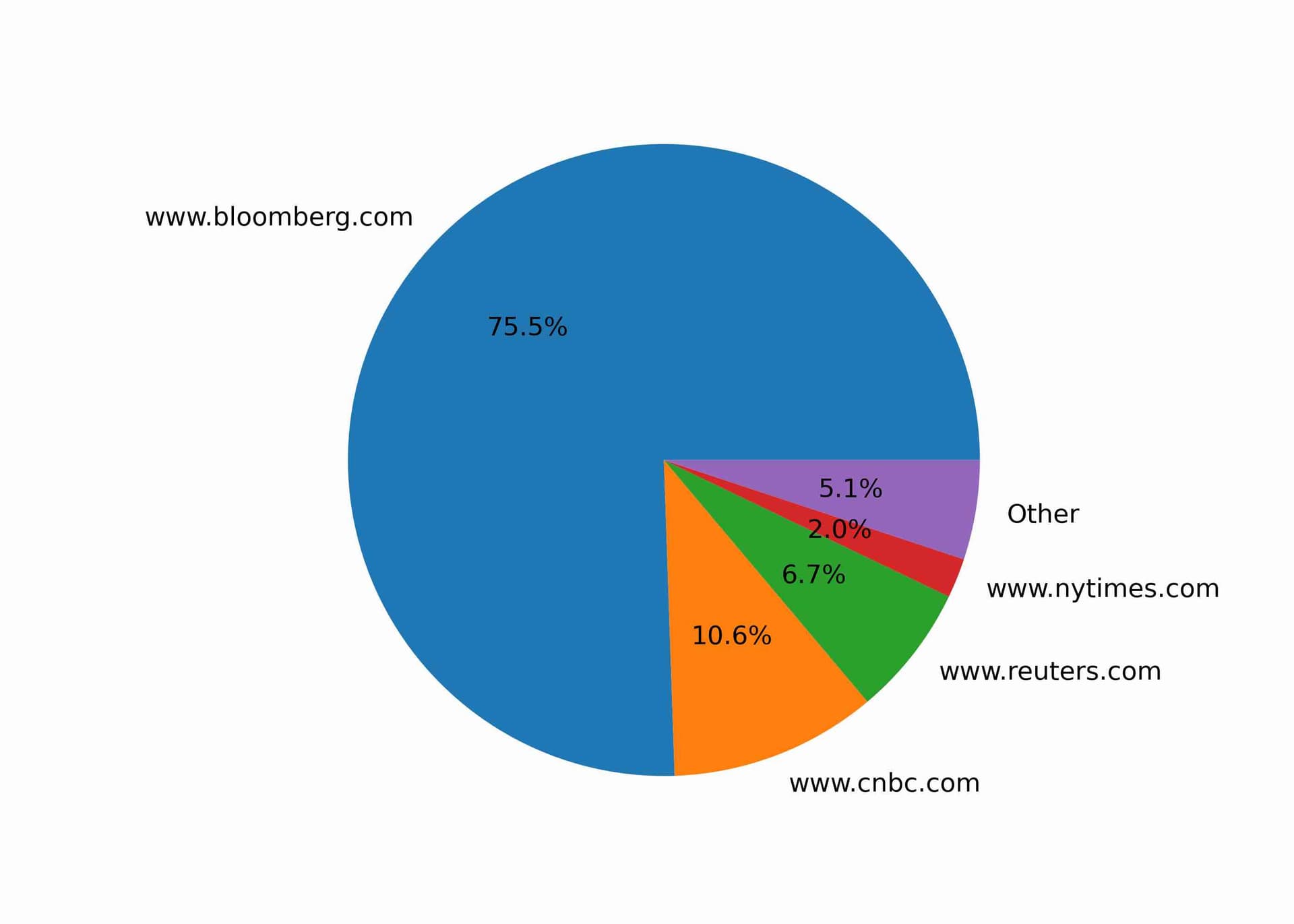
To avoid rate limiting, I created a custom web scraper to use and manage a pool of rotating proxies. I also used a custom rate limiter to ensure that I was not making too many requests to any given domain. Running the scraper from an OracleVM, I was able to scrape around 40 articles per minute and complete all 140,000 articles in around 2.5 days.
class Scraper:
"""
Scrapes a list of seed urls and calls the parser function to process each result.
The parser function should accept two arguments: the response object and the url.
The parser may pass a list of new urls to scrape with the addUrls(urls) method.
The scraper attempts to never scrape the same url twice.
"""
def __init__(self, seedURLs = [], parser = None, options = None):
emptyLogFile()
self.options = {
'cookieDirectory': './cookies/',
'scrapeThreads': 10,
'rateLimits': {},
'maxAttempts': 3,
'proxyUpdateInterval': 10
}
if options:
self.options.update(options)
self._cookies = loadCookies(self.options['cookieDirectory'])
self._parser = parser
self._urlQueue = queue.PriorityQueue()
self._finishedUrls = {}
self._finishedUrlsLock = threading.Lock()
self.addUrls(seedURLs)
self._threadNumber = self.options['scrapeThreads']
self._proxySessions = queue.Queue()
for proxy in self.verifyProxies(self.getProxies()):
self._proxySessions.put(proxy)
self._rateLimits = {}
self._rateLimitsLock = threading.Lock()
for domain in self.options['rateLimits']:
self._rateLimits[domain] = {
'limit': self.options['rateLimits'][domain],
'lastRequest': {}
}
def addUrls(self, urls):
""" Adds a list of urls to the list of urls to scrape. """
count = 0
with self._finishedUrlsLock:
for url in urls:
if url not in self._finishedUrls:
self._urlQueue.put((0, url))
count += 1
def run(self):
""" Starts the scraping threads and the proxy maintenance thread. """
scrapingThreads = []
for i in range(self._threadNumber):
t = threading.Thread(target = self._scrape)
t.start()
scrapingThreads.append(t)
proxyMaintThread = threading.Thread(target = self._maintainProxies)
proxyMaintThread.start()
for t in scrapingThreads:
t.join()
proxyMaintThread.join()
successfulScrapes = len([v for v in self._finishedUrls.values() if v])
print(f"Finished scraping. {len(self._finishedUrls)} urls scraped. {successfulScrapes} successful scrapes.")
I then split my dataset into a training set with 90,000 articles and into validation/testing sets with 10,000/40,000 articles respectively.
Training
Because the model weights are over 60GB, specialized computing was required for this training task. The training was done with a Google TPU-v3 generously donated by Google's TPU Research Cloud. I trained my model using the following hyperparameters:
{
"layers": 28,
"d_model": 4096,
"n_heads": 16,
"n_vocab": 50400,
"warmup_steps": 160,
"anneal_steps": 1530,
"lr": 1.2e-4,
"end_lr": 1.2e-5,
"weight_decay": 0.1,
"total_steps": 1700,
"tpu_size": 8,
"bucket": "peckham_tpu_europe",
"model_dir": "mesh_jax_stock_model_slim_f16",
"train_set": "stocks.train.index",
"val_set": {
"stocks": "stocks.val.index"
},
"val_batches": 5777,
"val_every": 500,
"ckpt_every": 500,
"keep_every": 10000
}
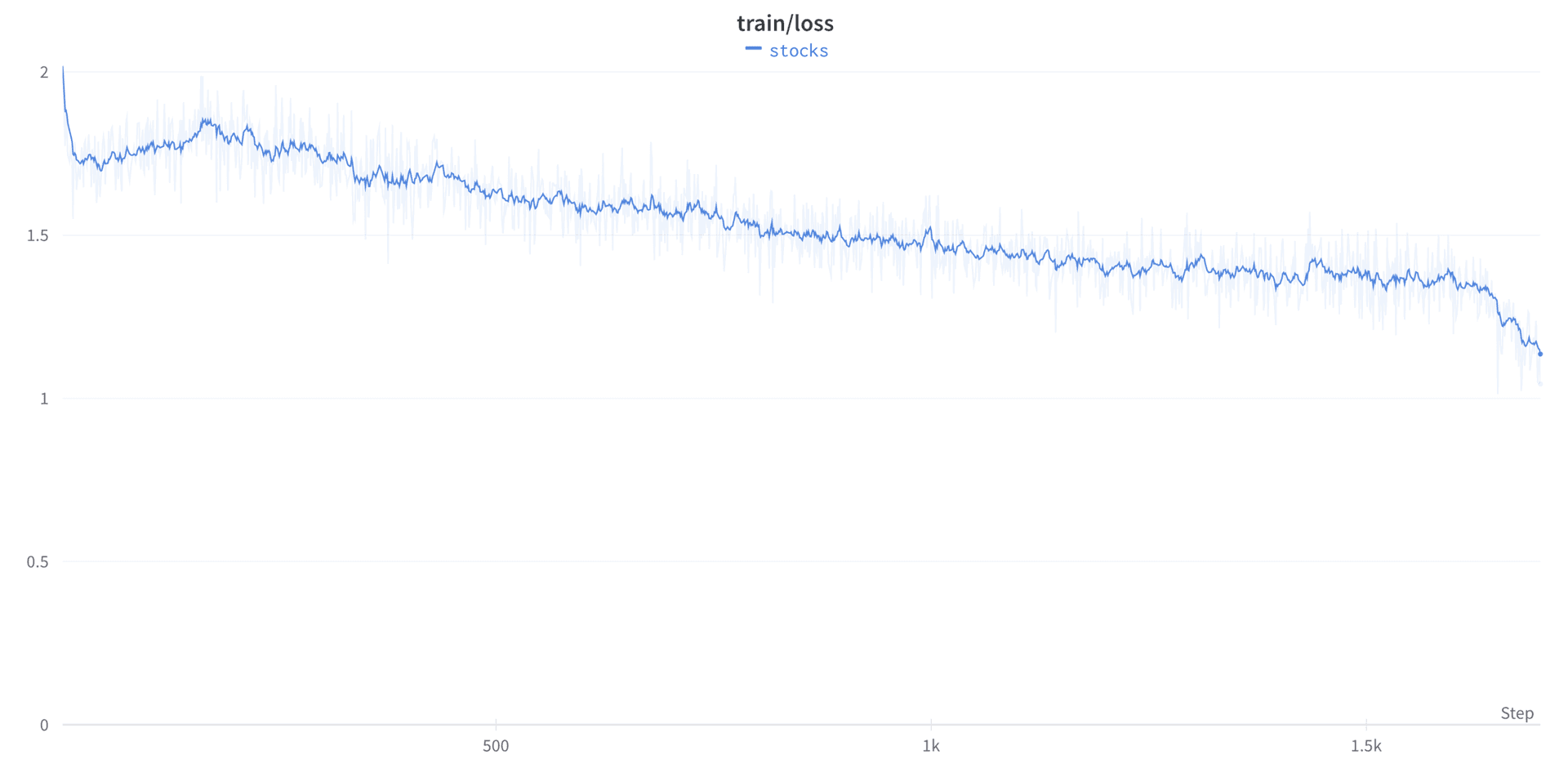
Training Loss
At first, I was encouraged by seeing a meaningful decrease in training loss, however, now I believe this was due to overfitting to the training set.
Results
Fine-tuned model: 50.58% (N=40K) correct guesses of stock price movement direction.
Standard GPT-J model: 50.63% (N=40K) correct guesses of stock price movement direction.
Human testing: 56% (N=120) correct guesses of stock price movement direction.
Conclusion
In my testing, GPT-J performs no better than random when predicting the direction of price movement based on a news story. Furthermore, fine-tuning the model does not improve prediction accuracy.
I believe these results are due to the following factors:
- The model (except for a small amount of fine-tuning) is not trained on financial data.
- The data was not cleaned well enough to remove noise.
- Text data is not a good representation of financial data. In other words, the model doesn't care about the actual numbers, only how well they "sound" in the context of the article.
- The articles may also not have enough information to predict price movement anyway. News is often considered a lagging indicator of price movement, and the articles I scraped were often published after the relevant price movement had already occurred.